SQL 처리 과정
1. Parsing
– Syntax check : 문법적 오류(키워드, 순서 등) 확인.
– Semantic check : 의미상 오류(존재하지 않는 object, 권한 등) 확인.
2. Library cache 확인
– 만약 실행계획이 있다면 그 계획으로 query 실행.
– 만약 실행계획이 없다면 아래의 3, 4번 수행.
3. 최적화 (SQL Optimizer)
– Optimizer가 실행계획을 결정. (hard parsing)
4. Row-Source 생성
5. Query 실행
Parsing
SQL 처리 과정을 한 번 거친 내부 프로시저를 재사용할 수 있도록 caching 해두는 메모리 영역을 Library Cache 라고 한다.
Soft Parsing
실행계획이 library cache에 존재하는 경우, 있는 실행계획을 그대로 사용한다. (Soft Parsing)
Hard Parsing
실행계획이 library cache에 존재하지 않는 경우, 실행계획을 만든다. (Hard Parsing) 따라서 대부분이 disk I/O인 DB 작업에서, CPU를 많이 사용하는 몇 안되는 작업 중 하나다. 그렇게 cost를 사용하여 만든 실행계획을 한 번만 사용하고 날린다면 비효율적이기 때문에 Library cache가 존재한다.
실행계획을 만드는 과정은, data dictionary에 있는 통계정보(System, Object)를 이용해서 여러 방법의 실행계획을 만들어보고, 그 중에 cost가 가장 적은 실행계획을 선택해서 해당 계획으로 쿼리를 수행시킨다.
- system 통계 : CPU 속도, Single Block I/O 속도, Multi Block I/O 속도 등.
- obejct 통계 : table, index, column(histogram을 포함) 통계.
Hint
1. table name을 hint에 줄 때 schema name까지 같이 주면 안된다.
select /*+ full(scott.emp) */ -- 무시됨.
from emp;2. table name에 alias를 사용했다면 hint에도 alias를 사용해야 된다.
select /*+ full(e) */
from emp e;3. hint를 여러 개 사용할 때 ,를 쓰면 뒤에 hint는 무시된다.
select /*+ full(e), index(e e_idx1) */ -- 뒤에 index hint는 무시됨.
from emp e;| 분류 | 힌트 | 설명 |
| 최적화 목표 | ALL_ROWS | 전체 처리속도 최적화 |
| FIRST_ROWS(N) | 최초 N건 응답속도 최적화 | |
| 액세스 방식 | FULL | Table Full Scan으로 유도 |
| INDEX | Index Scan으로 유도 | |
| INDEX_DESC | Index 역순으로 유도 | |
| INDEX_FFS | Index Fast Full Scan으로 유도 | |
| INDEX_SS | Index Skip Scan으로 유도 | |
| 조인 순서 | ORDERED | from절에 나열된 순서대로 조인 |
| LEADING | LEADING 힌트 괄호에 기술한 순서대로 조인 | |
| SWAP_JOIN_INPUTS | hash join 시, build input을 명시적으로 선택 | |
| 조인 방식 | USE_NL | NL join으로 유도 |
| USE_MERGE | sort merge join으로 유도 | |
| USE_HASH | hash join으로 유도 | |
| NL_SJ | NL semi join으로 유도 | |
| MERGE_SJ | sort merge semi join으로 유도 | |
| HASH_SJ | hash semi join으로 유도 | |
| 서브쿼리 팩토링 | MATERIALIZE | with문으로 정의한 집합을 물리적으로 생성하도록 유도 |
| INLINE | with문으로 정의한 집합을 INLINE 처리하도록 유도 | |
| 쿼리 변환 | MERGE | 뷰 머징 유도 |
| NO_MERGE | 뷰 머징 방지 | |
| UNNEST | sub query unnesting 유도 | |
| NO_UNNEST | sub query unnesting 방지 | |
| PUSH_PRED | 조인조건 push down 유도 | |
| NO_PUSH_PRED | 조인조건 push down 방지 | |
| USE_CONCAT | or 또는 IN-List 조건을 OR-Expansion으로 유도 | |
| NO_EXPAND | or 또는 IN-List 조건을 OR-Expansion으로 방지 | |
| 병렬 처리 | PARALLEL | table scan 또는 DML을 병렬 처리하도록 유도 |
| PARALLEL_INDEX | index scan을 병렬 처리하도록 유도 | |
| PQ_DISTRIBUTE | 병렬 처리 시 데이터 분배 방식 결정 | |
| 기타 | APPEND | Direct-Path Insert로 유도 |
| DRIVING_SITE | DB Link Remote query에 대한 최적화 및 실행 주체 지정(Local | Remote) | |
| PUSH_SUBQ | subquery를 가급적 빨리 필터링하도록 유도 | |
| NO_PUSH_SUBQ | subquery를 가급적 늦게 필터링하도록 유도 |
논리적, 물리적 저장 구조 및 단위
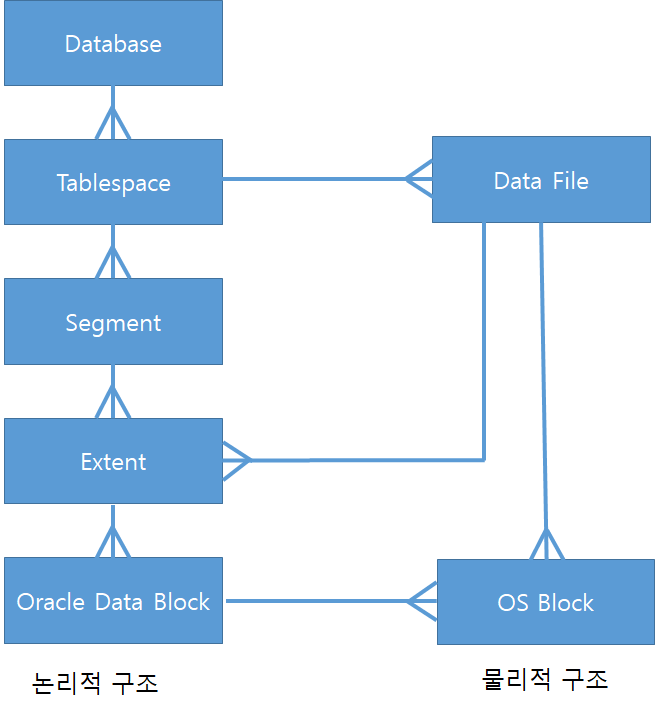
Oracle에서 block size는 8k(=8192)bytes가 default다. block은 읽고 쓰는 단위.
record 단위로 읽을 수 없다.
extent는 확장 단위.
segment에는 table, index, partition, LOB가 있다.
Access 방식
table이나 index를 읽는 방식으로 2가지가 있다.
Sequential Access
논리적 또는 물리적으로 연결된 순서에 따라서 차례대로 block을 읽는 방식.
index의 경우 : index leaf block(제일 밑단)은 각각 앞뒤를 가리키는 주소값을 통해 서로 논리적으로 연결되어 있다. 이 연결을 따라서 순차적으로 스캔한다.
table의 경우 : Oracle은 segment에 할당된 extent 목록을 segment header에 map으로 관리한다.
extent map은 각 extent의 첫번째 block address를 갖는다. 따라서 map에서 모든 extent의 address를 알 수 있기 때문에 이를 전부 스캔하면 table full scan이 된다.
Random Access
논리적 또는 물리적 순서를 따르지 않고, record 하나를 읽기 위해 한 block씩 접근(touch)하는 방식.
I/O
db buffer cache에 원하는 data가 존재한다면 disk를 가지 않아도 돼서 속도가 빠르다.
db buffer cache에 원하는 data가 없다면, disk에 가서 해당 data를 가져와야 하기 때문에 disk I/O가 발생하면서 query 수행 속도가 느려진다.
한 번 data를 가지고 db buffer cache에 올려놓으면, 해당 data가 오래 사용하지 않아 밀려서 사라지기 전까지는 disk를 다녀올 필요가 없어서, 처음 한 번만 느린 거고 그 뒤에는 빠르게 동작한다.
Logical I/O
SQL을 처리하는 과정에 발생한 총 block I/O를 말한다. 즉, memory I/O + physical I/O.
Physical I/O
disk에서 발생한 block I/O를 말한다.
Buffer Cache Hit Ratio = cache에서 찾은 block 수 / 총 block 수 * 100
= (logical – physical) / logical * 100
= (1 – physical/logical) * 100
위의 식을 조작하면
BCHR / 100 = 1 – physical/logical
– physical/logical = BCHR/100 – 1
physical/logical = 1 – BCHR/100
physical = logical * (1 – BCHR/100)
근데 위의 식에서 BCHR은 시스템 상황에 따라 달라지는 값이므로, physical을 줄이려면 logical을 줄여야 된다. 즉, logical I/O를 줄여서 물리적 I/O를 줄이는 것이 튜닝이다.
Single block I/O
한 block씩 caching 하는 방식.
index를 이용할 때는 기본적으로 index와 table 모두 single block I/O 방식이다.
Multi block I/O
여러 block씩 caching 하는 방식. disk 상에서 찾는 특정 block과 인접한 애들을 한꺼번에 읽어 미리 caching하는 개념이다.
* 인접한 애들 = 같은 extent에 속한 block. 즉, 아무리 multi block I/O여도 extent를 넘기진 못한다는 의미.
table full scan 시 multi block I/O 방식이다.
multi block I/O 단위를 키우면 성능적으로 좋아질 수 있다. OS마다 다르지만 보통 OS단에서는 1MB 단위로 I/O를 한다.
db_file_multiblock_read_count 파라미터 값을 128로 하면 8k(block size) * 128 = 1024KB = 1MB 가 된다.
즉, 최대한의 효율로 caching하게 된다.